
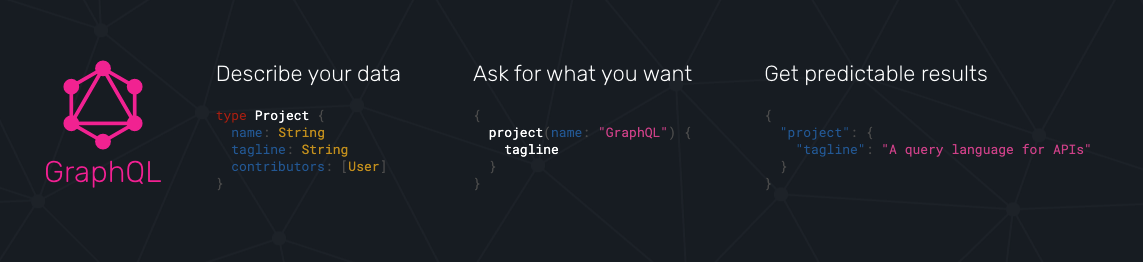
什么是 GraphQL ?
官网描述:GraphQL 是一个用于 API 的查询语言

GraphQL 是 FaceBook 2015 推出的一个查询语言,它不是一门新的编程语言,而是基于 HTTP 协议封装的 DSL, 简单来说它和我们熟悉的 RESTful API 一样,是用来查询接口,获取数据,当然,可以肯定的是它不是 KPI 轮子,而是真实服务于 FB 的各种业务场景中,现如今都还在维护
2023 年了,还在用传统 API : ) ? 接下来让我们简单了解一下
谁在使用 ?

目前比较知名的就是 GitHub, 它提供 REST API 和 [GraphQL](https://docs.github.com/en/graphql/overview/about-the-graphql-api)两套 API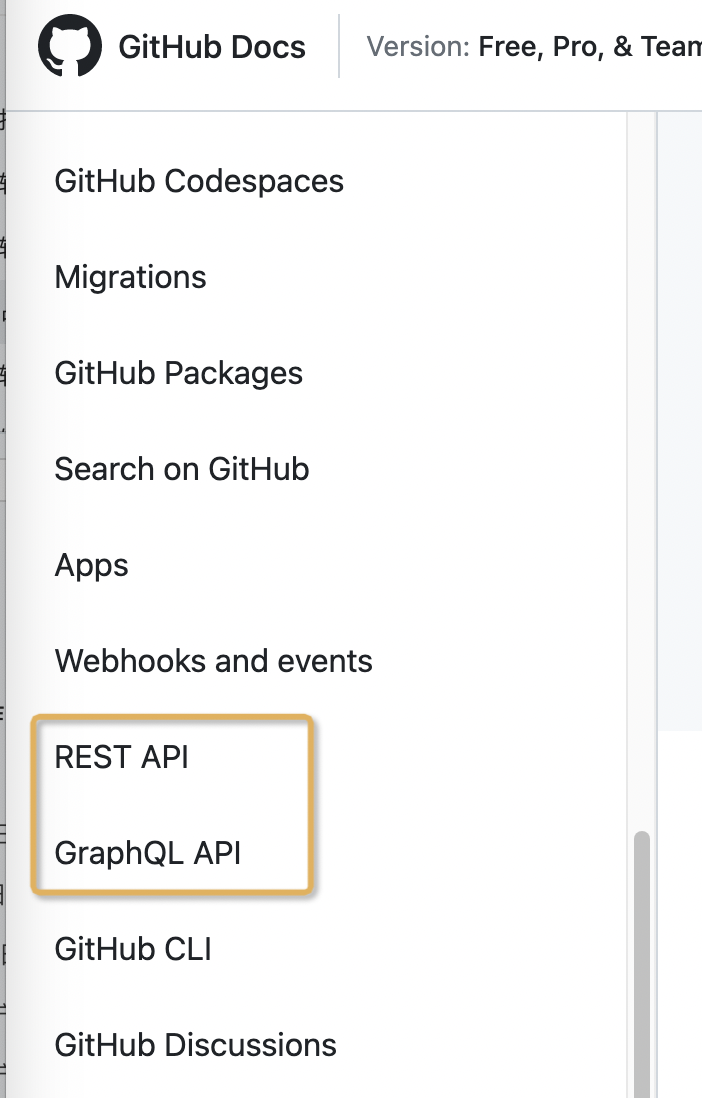

和 REST API 的区别 ?
我们常说的 接口 本质上是一个 HTTP资源地址,一个 Request 对应 一个 Response
:::info
GET /api/user
:::
:::info
GET /api/user/:id
:::
:::success
PATCH /api/user
:::
:::warning
POST /api/user
:::
:::danger
DELETE /api/user
:::
然后我们通过 XMLHttpRequest或者 Fetch API 来 "调接口"
1 | fetch('http://example.com/movies.json') |
1 | function reqListener () { |
然后接收后端返回的数据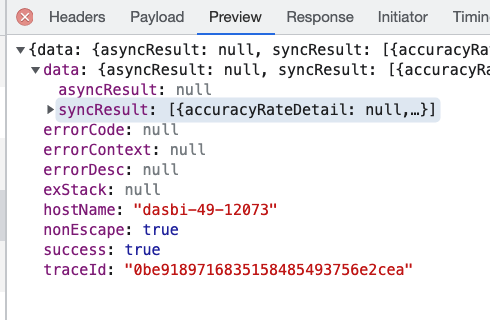
那么问题来了,如图为例,如果现在我不想接口中返回 traceId, 那么流程如下:
:::info
- 前端:后端大哥,麻烦把
/api/xx/xx这个接口的traceId去掉,我们前端现在业务不消费了,太冗余了 - 后端:好的,等我改一下,”找到对应的 Controller/Service, 然后去掉 traceId”
- 后端:我改了,部署好你试试
- 前端:好的,谢谢哥
:::
那么一个标准的 GraphQL查询是怎样的?
1 | { |
可以看到,非常的简洁,只需要声明你想查询的实体和需要的字段即可,那么如果想实现上面的诉求,去掉 traceId 我们只需要去掉查询即可
1 | { |

:::info
这个例子引出 GraphQL 很重要的一个特性,那就是查询返回的结果是**前端**说了算,即按需返回,查询和返回接口一致
:::
GraphQL Schema
如上面的例子,我们想查询 user.name和user.traceId, 这两个字段不是随心所欲,凭空猜测出来的,在 GraphQL 中,我们不再有一个一个 接口 的概念,而是对应实体的 Scheme, 有了它,我们可以对实体任意的 增删改查
1 | type User { |
这里的 name, traceId 在 GraphQL 中被称为 Field

类型系统大同小异,在 GraphQL 中也有自己的一套类型系统,对于 TypeScript 体操运动员们应该说不再话下,这里就不再赘述,查看详情
查询 (Query)
GraphQL 中的 Query可以类别 REST API中的 GET请求,但能力更丰富
获取一组数据
1 | GET /api/users |
1 | { |
获取单个数据
1 | GET /api/user/1 |
1 | { |
根据条件获取数据
在传统 REST API场景,比如我们想调用一个接口,接口信息中返回这个用户的工资,但是工资只给老板看,一种是给后端标识,让后端来动态返回,一种是全量请求后,前端手动隐藏
1 | GET /api/user/1 |
而在 GraphQL 中,我们可以通过 指令 @include() @skip 来实现在前端查询时就动态控制字段的返回
@include(if: Boolean)白名单,满足则返回@skip(if: Boolean)黑名单,满足则跳过
1 | query User($isOwner: Boolean!, $isMyXiaoJin: Boolean = false) { |
当然,查询还有很多有意思的玩法,如:别名, 片段复用, 操作名, 篇幅有限不一一列举 查看更多
变更 (Mutations)
GraphQL 中的 Query可以类别 REST API中的 POST请求,用来做数据的变更,对于前端的话,用过 Vuex的话会比较熟悉 Mutation这个概念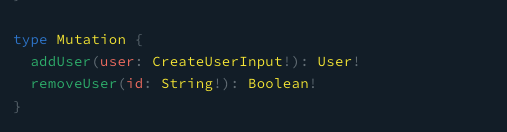
插入一条数据
1 | POST /api/user/add |
1 | mutation AddUser($user: User!) { |
解析器 (Resolver)
不管是 query 还是 mutation, 我们的数据不可能凭空而来,我们也需要和数据库建立连接,然后 CRUD 一波,这一部就通过 Resolver完成
1 | import { Args, Resolver, Query } from '@nestjs/graphql' |
GraphQL 在实际项目中如何使用?
:::info
本地 Playground 演示地址:http://localhost:3000/graphql
:::
生态
GraphQL 最开始只有 Node.js 的实现,后经过慢慢发展,在很多编程语言中都有了对应实现,分为 客户端和 服务端

我们这里使用 Nest.js (一个基于 Node.js 后端框架,注意不是 Next.js) 做演示
:::warning
注意:不要对框架和其他细节过多在意,文中大部分为伪代码,仅供示意
:::
与 TypeScript 结合
不管前端还是后端 (Node.js 生态), 目前主流的都是使用 TypeScript, 那么与 GraphQL结合首先会遇到第一个问题,那就是类型,上面讲到了 GraphQL Schema, 有自己的一套类型系统,也就意味着通常来说写两套类型,一套 **xx.ts**, 一套**xx.gql**
1 | interface Salary { |
一个笨方法就是写两套,但是不管是维护成本还是开发成本都会大大增加,好在 Nest.js中集成了根据 TS类型自动生成 GraphQL类型的方案 - type-graphql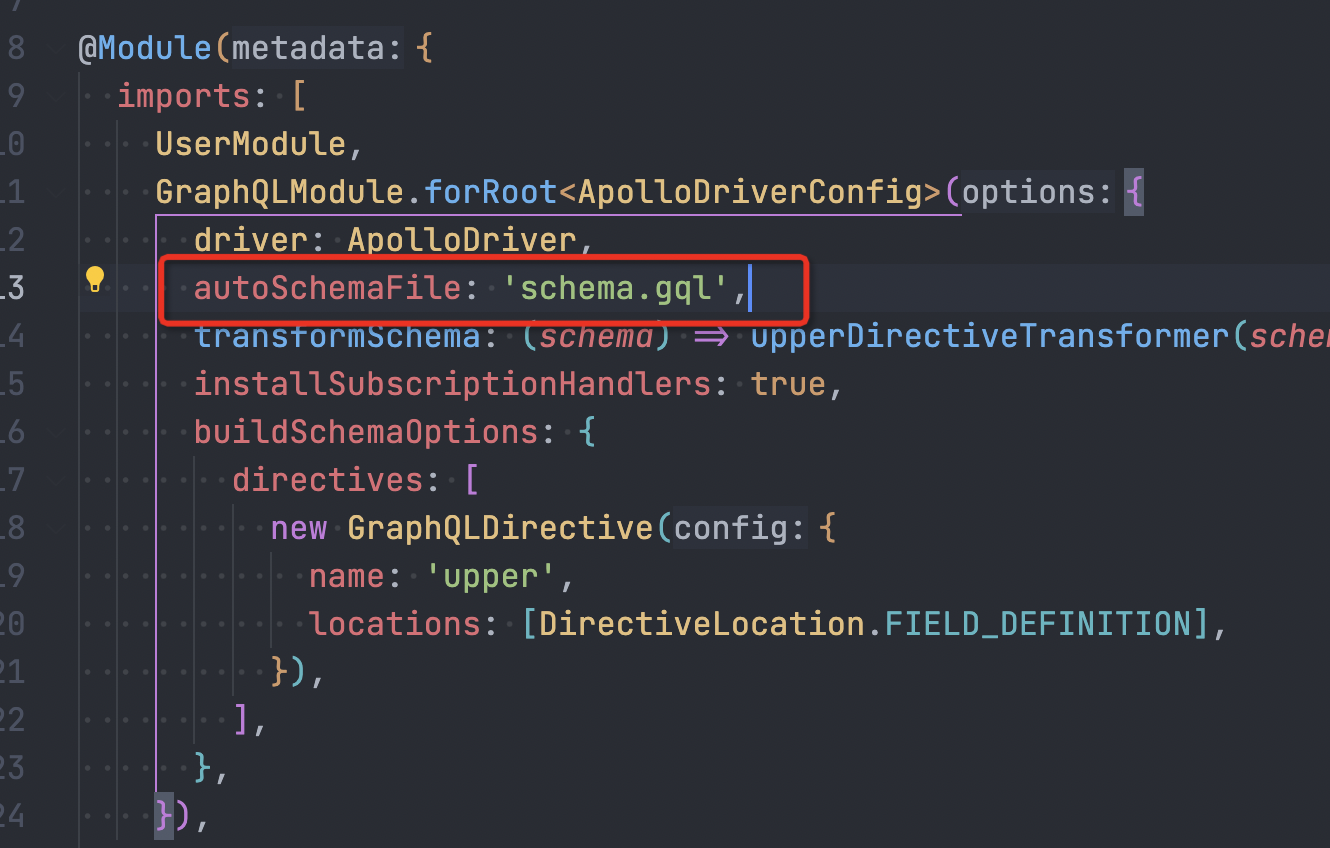
上面例子中的 User , 如下图,是一个普通的 Ts Class, 那么 @Field 装饰器就对应 GraphQL 的 Field
然后 Node 服务启动的时候,会自动生成,不需要关心 GraphQL 层面的类型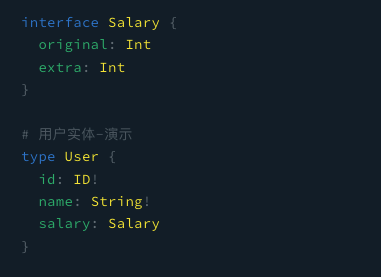

Resolver
GraphQL 的 Resolver 可以理解成,传统 REST 的 Controller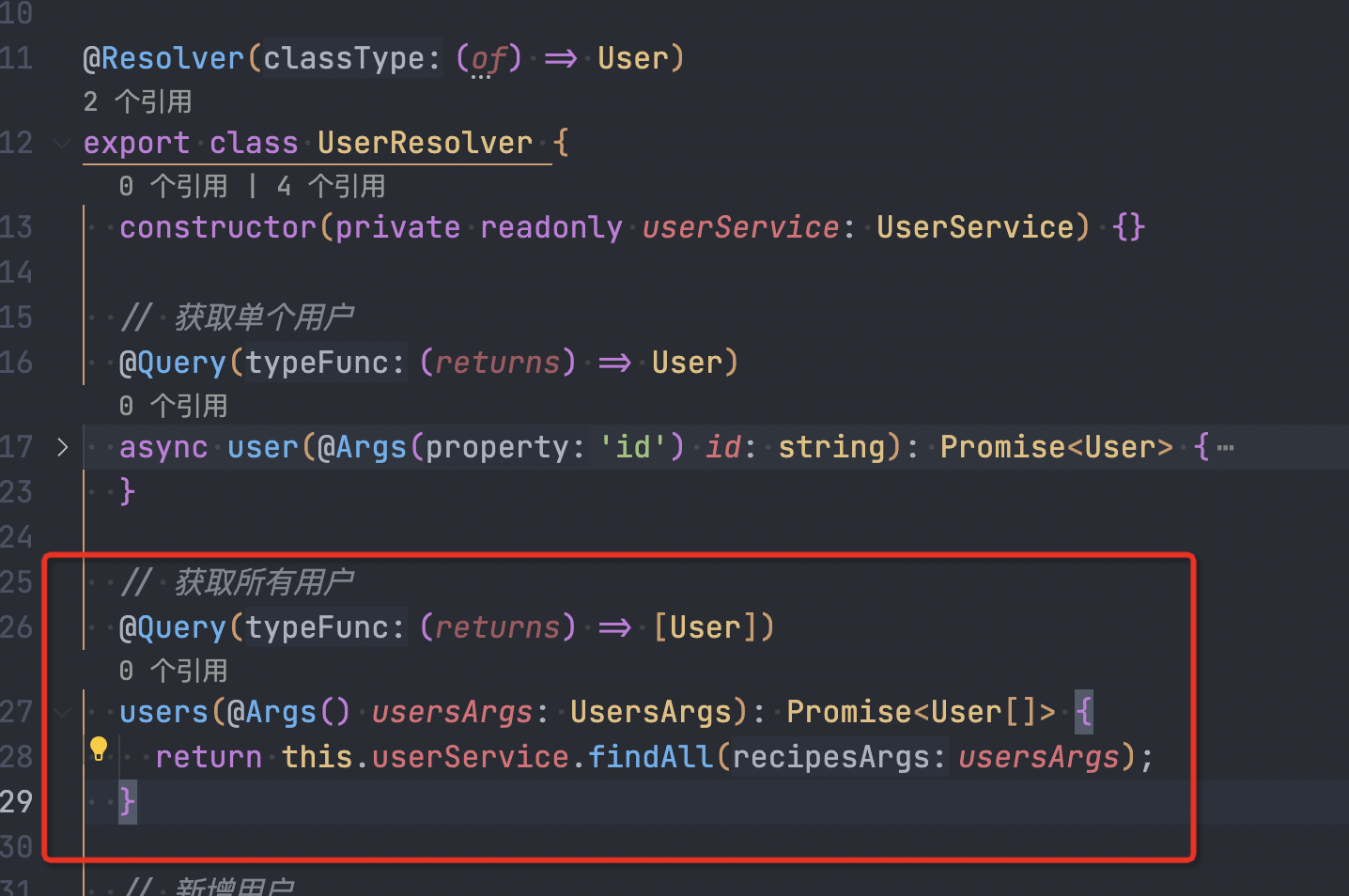
当一个 Query 发起查询时
1 | { |
Resolver 需要做的就是处理这个查询,查询 user 这个实体,返回 id和 name这个数据,需要返回什么前端说了算
而 Query 是可以嵌套的,想象一下 如果我还想查询 user下的 salary 通常这些数据不会存存在一张数据表中,那么 salary 通常对应 Salary实体,那么 salary 也可以对应一个 Resolver, 也就是 salary是 user的一个子查询,而不是传统的通过 left join之类的处理方式聚合数据,最后 GraphQL会帮你聚合其他,统一在 user 查询中返回
1 | { |
1 | () |
如果按照非常变态的领域模型来看的话,Query 的 Field 可以拆的很细,其对应的 Resolver 也可以很多,也就意味着 一个 Field 对应数据库的一条查询。
如果是批量查询话,也就意味着 query 会查询多次,想象一下如果我们现在查询所有的 users, 对应的 Resolver如下

query 如下:
1 | { |
那么每一条 salary对应的 query 会查询多次,比较冗余,(也就是 N+1 问题) , 有问题就有解法,GraphQL 官方提供了 dataloader 来解决这个问题,它可以对查询进行缓存和聚合,可以简单的理解成它是一个防抖函数,当所有 Field 的 Query 完成后,统一触发一次批量查询,这里简单了解即可。

Query 查询

Mutations 变更

Docker 部署
由于 docker 里面没有写入文件的权限,这样会带来一个问题,由于启动应用的时候
1 | ... |
会自动生成 schema 文件,也就是 fs.writeFile 这样会导致 docker 启动不了,所以需要小小修改下 GraphqlModule 的配置
- 方法 1 :
1 | import { Module } from '@nestjs/common' |
在 development 的时候 会生成 schema.gql, 在 production 环境下 关闭自动生成
同时指定 typePaths 为 schema.gql 这样既可解决
- 方法 2 :
首先 使用 type-graphql 提供的 buildSchema, 在每次 构建镜像的时候 将这个文件 copy 进去既可
1 | import { buildSchema } from "type-graphql"; |
权限验证
:::warning
这个不同的框架/库处理方式,仅做简单介绍,不过过多在意代码细节
:::
在 express中 可以通过 中间键 拦截 request 来做权限验证,在 Nest.js中 可以很方便的 使用 Guards 实现
1 | import { Args, Resolver, ResolveProperty } from '@nestjs/graphql' |
由于 GraphQL 有一个 context 的概念 可以通过 context 拿到 当前的 request, 然后可以配合常用的 JWT做一些权限验证,在每次 Resolver 处理 Query 的时候,没有权限就直接返回 401 之类的处理
1 | // auth.guard.ts |
道理我都懂,为什么 GraphQL 不火?
这里引用 2016 年,一个连 Vue 都不会的楼主的回答
说下自己的理解:
- 可以但没必要:想象一下大部分业务场景,我如果就是一个后端管理系统,倘若我前端 React 全家桶,后端 Java SpringBoot 全家桶 JPA/lombok 一把唆,分分钟搞定 CRUD, 阁下该如何应对?生态摆在这里,正所谓当你不知道你该不该用 GraphQL 时,那么就是不需要,为了用而用,大可不必。
- 就差一个程序猿了:如果业务特别复杂,场景特别适合用 GraphQL, 那么问题来了,哪个倒霉蛋来接?
- 前端:后端你接一下吧,帮我写好 Resolver, 我直接想查啥就查啥,不是爽歪歪?
- 后端:你爽了,那业务逻辑是放在我这边还是你这边?听下来我只需要分好模型,每个模型写好各自的 Resolver, 你来写业务逻辑,自己拼 query 就好了
- 前端:那这样吧,你加一个 BFF, 保证你后端逻辑的干净,业务逻辑在 BFF 处理
- 后端:那你用 Node 搭一个 BFF 吧,这些事情你们来做要好一点
- …
如果是全栈团队,前后端都自己来搞,用 GraphQL 还是比较舒服,一旦分工明确,通常的一种妥协方案就是加 BFF, 而且是前端用 Node 搭 BFF, 来做各种适配和转换,这些都是属于前端的工作,个人认为是得不偿失
最后
本文简单介绍了 GraphQL 的一些基本概念 和一些实际的使用场景,除此之外还有很多炫酷的 特性, 篇幅有限,就不一一列举了,文中示例代码,可在 GitHub 中 查看.